1. censure. Функция определяет наличие мата (нецензурных, матерных слов) в тексте. Возвращает false, если мат не обнаружен, иначе обнаруженное матерное слово. Алгоритм достаточно надежен и быстр, в т.ч. на больших объемах данных. Метод обнаружения мата основывается на корнях и предлогах русского языка, а не на словаре, поэтому скорость очень высока.
2. cp1251_to_utf8_recursive. Функция для перекодировки данных произвольной структуры из кодировки cp1251 в кодировку UTF8.
3. cp1259_to_utf8. Конвертирует текст из кодировки cp1259 и cp1251 в кодировку UTF-8.
4. html_template. HTML-ориентированный шаблонизатор с автоматическим квотированим значений меток-заменителей.
5. html_words_highlight. «Подсветка» найденных слов для результатов поисковых систем.
6. hyphen_words. Расстановка «мягких» переносов в словах.
7. is_utf8. Возвращает true усли переданная строка — правильный UTF-8, иначе false.
8. php2js. Конвертирует данные PHP из scalar, array и hash в данные JS в scalar/array/hash.
9. strip_tags_smart. Более продвинутый аналог strip_tags() для корректного вырезания тегов из html кода. Возможности:
— корректно обрабатываются вхождения типа «a < b > c».
— корректно обрабатывается «грязный» html, когда в значениях атрибутов тагов могут встречаться символы < >.
— корректно обрабатывается разбитый html.
— вырезаются комментарии, скрипты, стили, PHP, Perl, ASP код, MS Word теги.
— автоматически форматируется текст, если он содержит html код.
— защита от подделок типа: «<script>alert(‘hi’)script>».
10. textarea_rows. Вычисляет высоту области редактирования текста (<textarea>) по значению и ширине.
11. ucs2_to_utf8. Преобразует строку из кодировки UCS-2 в UTF-8, без использования iconv.
12. utf8_autoconvert_request_charset. Перекодирует значения элементов массивов $_GET, $_POST, $_COOKIE, $_REQUEST, $_FILES из кодировки cp1251 в UTF-8, если необходимо. Побочным положительным эффектом функции является защита от XSS атаки с непечатаемыми символами на уязвимые PHP функции.
13. utf8_check. Пытается определить, находится ли строка в кдировке Unicode.
14. utf8_convert_case. Конвертирует регистр букв в строке в кодировке UTF-8.
15. utf8_escape. Перекодирует строковые объекты так, чтобы они читались везде.
16. utf8_html_entity_decode. Конвертирует все HTML-entities в символы UTF-8.
17. utf8_html_entity_encode. Конвертирует спецсимволы UTF-8 в HTML-entities.
18. utf8_simple_search_sql. Создает условия для простого поискового SQL запроса, основанного на LIKE и REGEXP.
19. utf8_str_limit. Обрезает текст в кодировке UTF-8 до заданной длины, причём последнее слово показывается целиком, а не обрывается на середине.
20. utf8_strlen. Расширенная функция strlen() для работы со строками в utf-8.
21. utf8_substr. Расширенная функция substr() для работы со строками в utf-8.
22. utf8_ucfirst. Преобразует первый символ строки в кодировке UTF-8 в верхний регистр.
23. utf8_ucwords. Преобразует в верхний регистр первый символ каждого слова в строке в кодировке UTF-8, остальные символы каждого слова преобразуются в нижний регистр.
24. utf8_unescape. Функция декодирует строку в формате %uxxxx в строку формата UTF-8.
25. utf8_unescape_recursive. Рекурсивный вариант utf8_unescape().
26. utf8_unescape_request. Корректирует глобальные массивы $_GET, $_POST, $_COOKIE, $_REQUEST, декодируя значения в юникоде, закодированные через функцию javascript escape() ~ “%uxxxx”.
 31 июля стартует iCamp 2008 – первая в России неформальная конференция интернет-активистов, проходящая в формате barcamp.
31 июля стартует iCamp 2008 – первая в России неформальная конференция интернет-активистов, проходящая в формате barcamp.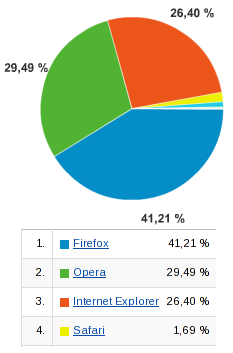 Это официальная дата релиза отличного браузера и день, в который разработчики установят мировой рекорд по числу загрузок программы за сутки. И мы им в этом поможем.
Это официальная дата релиза отличного браузера и день, в который разработчики установят мировой рекорд по числу загрузок программы за сутки. И мы им в этом поможем. «Облако тегов» или «Облако меток» (англ. tag cloud) — визуальное представление списка ярлыков. Частота упоминаний, поисков, ссылок в интернете с определенного сайта неких слов, терминов, имен, отображается в виде изображения этих слов в формате гиперссылок. Размер изображения тем больше, чем выше релевантность данного слова.
«Облако тегов» или «Облако меток» (англ. tag cloud) — визуальное представление списка ярлыков. Частота упоминаний, поисков, ссылок в интернете с определенного сайта неких слов, терминов, имен, отображается в виде изображения этих слов в формате гиперссылок. Размер изображения тем больше, чем выше релевантность данного слова.
 Вдогонку к заметкам о
Вдогонку к заметкам о 
